Kādi ir izplatītākie latviešu valodas vārdi un kā tie mūs raksturo
Savulaik, izstrādājot Latviešu moderno tastatūru, veicu izpēti par burtu sadalījumu latviešu valodā, bet tagad, latviskojot Espeak teksta — runas sintezatoru, man parādījās interese arī par izplatītākajiem latviešu valodas vārdiem.
Lai arī cik tas nebūtu dīvaini, Latvijas Universitātes Mākslīgā intelekta laboratorija savā lapā http://www.korpuss.lv/ nedod (vieglu) atbildi uz tādu "vienkāršu" jautājumu, kā "kādi ir izplatītākie latviešu valodas vārdi?".
Lai arī es varēju iet līdzīgu ceļu kā iepriekš un izmantot tikai dažus literārus darbus, šoreiz es vēlējos savākt plašāku tekstu paraugu, tāpēc nolēmu "saskrāpēt" to no tīmekļa vietnēm.
Saturs
Satura savākšana un apkopošana
Skrāpējot tīmekļa saturu, lielākās grūtības sagādā izvilkt no lapu HTML koda tikai lapai unikālo tekstu, atmetot iesākumu, nobeigumu, paneļus, reklāmas un citas vietnēs atkārtojošās lietas. Tomēr, izpētot HTML kodu parasti var atlasīt kādu zīmīgu HTML elementu, kurā ir galvenais lapas teksts. Pēc dažādiem neveiksmīgiem mēģinājumiem kā datu avotus izmantoju divas tīmekļa vietnes: vikipēdiju un Delfi un TVNET ar sekojošu Bash skriptu:
echo "Getting content from Wikipedia ..."
wget -e robots=off -r -np -l3 -R *.css,*.js,*.png,*.JPG,*.jpg,*.jpeg,*.ogg,*.svg,*.gif -N --local-encoding=utf8 https://lv.wikipedia.org/wiki/Special:RecentChanges >wget.log 2>&1
echo "Getting content from Delfi ..."
wget -e robots=off -r -np -l3 -R *.css,*.js,*.png,*.JPG,*.jpg,*.jpeg,*.ogg,*.svg,*.gif -N --local-encoding=utf8 https://www.delfi.lv/ >wget.log 2>&1
echo "Getting content from Tvnet ..."
wget -e robots=off -r -np -l4 -R *.css,*.js,*.png,*.JPG,*.jpg,*.jpeg,*.ogg,*.svg,*.gif -N --local-encoding=utf8 http://www.tvnet.lv/ >wget.log 2>&1
rm tmp.txt 2>/dev/null
echo "Aggregating content of Wikipedia ..."
for i in $(find lv.wikipedia.org/wiki/ -type f)
do
# use hxselect to get only wikipedia article and then
# cut off end part of wikipedia articles which has notes and references with sed, then
# grep out just numbers and convert it to lowercase
cat "$i"|hxselect "#mw-content-text" 2>/dev/null \
| xidel - --xquery "//p" 2>/dev/null \
|grep -vE "\s*?[0-9]+\.\s*.*|^\s*$|^Ārējie rīki|^Šajās lapās|^Šiet ir nesen"|sed 's/.*/\L&/' >> tmp.txt
done
echo "Aggregating content of Delfi ..."
for i in $(find www.delfi.lv/ -type f)
do
# Similarly to Delfi use xidel
cat "$i" 2>/dev/null|xidel - --xquery "//p" 2>/dev/null|grep -vE '^\s*$' |sed 's/.*/\L&/' >> tmp.txt
done
echo "Aggregating content of Tvnet ..."
for i in $(find www.tvnet.lv/ -type f)
do
# Similarly to Delfi use xidel
cat "$i" 2>/dev/null|xidel - --xquery "//p" 2>/dev/null|grep -vE '^\s*$|\.\.\.[[:digit:]]*$' |sed 's/.*/\L&/' >> tmp.txt
done
echo "Sorting words..."
# Replace "word terminator" symbols with linebreaks
# I use custom java app to support unicode characters
cat tmp.txt|mytr "~*#,;.:?! ()[]{}<>'\"\/\t“”„«»:…^+=→—–−-×·•°²³%‰ ′″" \
"\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n" \
|sort > tmp-sorted.txt
echo "Counting words..."
cat tmp-sorted.txt|uniq -c > word-count.txt
echo "Sorting counted words..."
sort -rn word-count.txt > word-count-sorted.txt
Darbinot lapu satura savākšanu ar tail -f wget.log vēroju wget žurnāla failu un, ieraugot, ka wget savāc pārāk daudz drazas, attiecīgi pielāgoju tā parametrus. Kad jutos daudzmaz apmierināts ar rezultātiem, atļāvu skriptam iziet līdz galam.
(Ja lietojat vai esat spiests lietot Windows operētājsistēmu, tad varat mēģināt izmantot šādu risinājumu ar Linux virtuālo mašīnu, Cygwin, vai arī jauno Windows 10 Ubuntu iekš Windows iespēju. Bet ilgtermiņā, protams, pareizāk ir pāriet uz Linux.)
Teksta statistika
Pēc vairāku stundu gaidīšanas, ar man pieejamo 2×10Mb/s tīkla pieslēgumu, savācu:
- no vikipēdijas ap 58k lapu 3,2G apjomā,
- no Delfi ap 15k lapu 1,5GB apjomā,
- no TVNET ap 25k lapu 2,9GB apjomā.
No šī kopējā nepilnu 2G datu apjoma izvilku unikālu tekstu ar 14M vārdu "tikai" 104MB apjomā. Ap 2M vārdu tur bija dažāda draza: gari skaitļi (gadi, skaitļi kopā ar mērvienībām, kodi un identifikatori) angļu (tajā skaitā angļu valodas vārdi no neizvākta JavaScript un neattīrīta HTML koda) un krievu valodas vārdi, kā arī dažādas nenofiltrēta Unicode rakstzīmes (pasvītrojumzīme, bultiņas, pēdiņas u.tml.). Atmetot "vārdus", kas atkārtojās tikai vienu reizi, pāri palika ap 10M (10'360'701) vārdu.
Lai saskaitītu kopā sugas vārdus gan teikuma sākumā, gan citur, visus vārdu burtus pārvērtu uz mazajiem. Pēc tam, tīrot drazu, izmetu angļu un krievu valodu sugasvārdus, bet atstāju internacionālismus, zīmolus un dažādus izplatītus saīsinājumums.
Vārdu izplatība
Rezultātā ieguvu sekojošu 100 sastopamāko vārdu sadalījumu (tabulā norādīts vārds, tā parādīšanās skaits un attiecība promilēs no kopējā vērā ņemto vārdu skaita):
| Vārds | Skaits | ‰ | Vārds | Skaits | ‰ | Vārds | Skaits | ‰ | Vārds | Skaits | ‰ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| un | 403926 | 39,0 | pēc | 34983 | 3,4 | ļoti | 18547 | 1,8 | gada | 12514 | 1,2 |
| ir | 297076 | 28,7 | gan | 34288 | 3,3 | valsts | 18485 | 1,8 | labi | 12317 | 1,2 |
| ar | 155089 | 15,0 | lv | 33897 | 3,3 | viņš | 17843 | 1,7 | kopā | 12215 | 1,2 |
| no | 122068 | 11,8 | jo | 30222 | 2,9 | tās | 17667 | 1,7 | tomēr | 12080 | 1,2 |
| par | 119236 | 11,5 | visas | 29971 | 2,9 | kaut | 17444 | 1,7 | tagad | 11967 | 1,2 |
| ka | 114194 | 11,0 | es | 28531 | 2,8 | tik | 17441 | 1,7 | viņi | 11873 | 1,1 |
| arī | 92503 | 8,9 | ne | 28406 | 2,7 | tur | 17248 | 1,7 | mēs | 11745 | 1,1 |
| kā | 88978 | 8,6 | pie | 28084 | 2,7 | tu | 17025 | 1,6 | viens | 11639 | 1,1 |
| kas | 85982 | 8,3 | savu | 26124 | 2,5 | būs | 16959 | 1,6 | piemēram | 11636 | 1,1 |
| bet | 80240 | 7,7 | ziņas | 25373 | 2,4 | tie | 16667 | 1,6 | atrodas | 11626 | 1,1 |
| to | 76770 | 7,4 | latvijas | 25307 | 2,4 | viņa | 16056 | 1,5 | šajā | 11617 | 1,1 |
| uz | 72351 | 7,0 | līdz | 24945 | 2,4 | laikā | 15831 | 1,5 | viss | 11530 | 1,1 |
| vai | 67314 | 6,5 | ievērojamas | 23946 | 2,3 | nākamais | 15680 | 1,5 | kurš | 11370 | 1,1 |
| nav | 61922 | 6,0 | © | 23864 | 2,3 | pret | 15660 | 1,5 | pirms | 11023 | 1,1 |
| tas | 55387 | 5,3 | paturētas | 23830 | 2,3 | būtu | 15649 | 1,5 | viņu | 10891 | 1,1 |
| tā | 54585 | 5,3 | tiek | 22815 | 2,2 | daudz | 15305 | 1,5 | visi | 10651 | 1,0 |
| ja | 52158 | 5,0 | kur | 22766 | 2,2 | iepriekšējais | 15262 | 1,5 | tev | 10632 | 1,0 |
| lai | 48433 | 4,7 | vēl | 22536 | 2,2 | visu | 14779 | 1,4 | cik | 10520 | 1,0 |
| var | 45558 | 4,4 | kad | 22527 | 2,2 | lasīt | 14615 | 1,4 | normas | 10480 | 1,0 |
| bija | 44876 | 4,3 | bez | 21084 | 2,0 | tika | 14289 | 1,4 | latvijā | 10327 | 1,0 |
| tad | 43360 | 4,2 | būt | 20998 | 2,0 | šo | 14256 | 1,4 | komentāru | 10156 | 1,0 |
| jau | 42559 | 4,1 | man | 20534 | 2,0 | taču | 13997 | 1,4 | aicina | 10095 | 1,0 |
| ko | 40182 | 3,9 | pa | 20516 | 2,0 | tam | 13265 | 1,3 | saglabāt | 10058 | 1,0 |
| tikai | 36162 | 3,5 | pat | 20266 | 2,0 | vairāk | 13231 | 1,3 | mums | 10053 | 1,0 |
| tiesības | 35764 | 3,5 | nu | 18593 | 1,8 | mūsu | 12588 | 1,2 | noteikumi | 9932 | 1,0 |
Sekojošā attēlā 50 izplatītāko vārdu sadalījums ir parādīts grafikā (klikšķiniet uz attēla, lai to apskatītu lielāku):
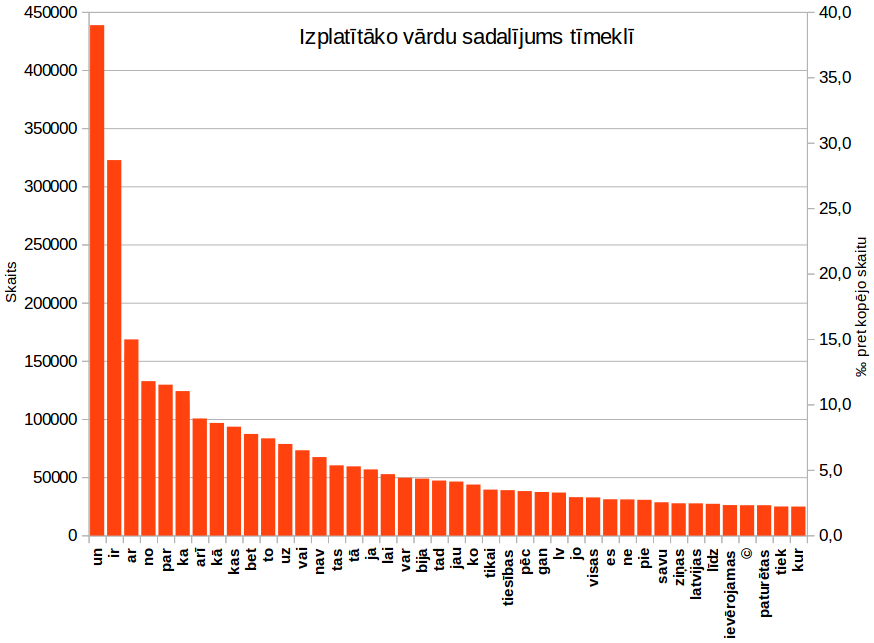
100 izplatītākie vārdi kopā sastāda ap 34% no visiem vārdiem. Lai arī centos izfiltrēt lapās atkārtojošos saturu ar hxselect, xidel un teksta apstrādes rīkiem, vietnēm raksturīgi vārdi "topā" tomēr ir ielavījušies. Piemēram, labot, satura rādītājs, saites, bet, no otras puses, tīmekli lietojot, šie vārdi ir sastopami pat vēl biežāk, tikai mēs iemācāmies tiem nepievērst uzmanību.
50% no visa teksta sastāda sekojoši 400 vārdi:
ko tikai tiesības pēc gan lv jo visas es ne pie savu ziņas latvijas līdz
ievērojamas © paturētas tiek kur vēl kad bez būt man pa pat nu ļoti valsts viņš
tās kaut tik tur tu būs tie viņa laikā nākamais pret būtu daudz iepriekšējais
visu lasīt tika šo taču tam vairāk mūsu gada labi kopā tomēr tagad viņi mēs
viens piemēram atrodas šajā viss kurš pirms viņu visi tev cik normas latvijā
komentāru aicina saglabāt mums noteikumi vien kāds tiem pasaules gadu iestādēm
iztikt komentāriem lasītājus lietotājam kuri pieeju kuras patur ziņot tāpēc
nekā šī elementāras pieklājības tolerantiem attiecīgajām liegt tiesībsargājošām
rupjībām nevis varētu tāpat kuru viena starp rīgas nevar jūs citu km savā kura
te cilvēki pats kādu pievienots eiropas tieši jeb vispār avots gadā savas
latviešu parasti visiem foto vienu maijs savukārt cilvēku kurā iespējams
krievijas varbūt dziesmu jums utc nebija kam vieta esi neko darba daļa laika
šis kāda trīs tām šīs laiku tos viņam tajā vietu novada šobrīd vairs dēļ lapas
protams asv kāpēc dziesma ap viņiem labāk vismaz vietā rakstu krievu gadus
katru bieži maijā pasaulē īpaši notiek darbu šeit atkal vienkārši laikam bērnu
tālāk sporta sevi pilnīgi jūsu jūras esmu paldies latvija tiešām eiro zemes
vajag citiem neviens dzīvot ūdens vējš cilvēks raksta pilsētas tiks auto iela
reizi vienmēr spēles dzīvo viņas nekas kultūras hokeja dienu gadījumā sava
vietas šodien visus tādu gadiem izbaudīt reizes video tai paši diskusija justs
mājās gads nekad citi jābūt tautas neliels krievija jā veido nevarēju lielākā
sev zemē kuriem liels pagasta dienas spēlē valodā iet tv tāds katrs izmanto
divas mani ukrainas tādēļ valodas sāk aptuveni gandrīz uzskata kategorijā
galvenais dzīves esam bijis liela cilvēkiem daudzi naudu pirmo kamēr noteikti
visa grupas naudas komanda vēlāk as komandas apmēram citas zem vienā bērniem
ielu daļā mūzikas redzamas mājas pašu centrs nebūtu centra laiks izmantot
mairis dvēseli nevajag šim nozīmē nemaz angļu tāda valstu kādas kara ielas kopš
valsti jaunību varēja nedaudz liegts pati bērni krievijai sauc saka pirmā kuram
lapu šie pirmais turklāt iedzīvotāju neļauj savus nebūs mazāk līdzi izskatās
pēdējā ģimenes cilvēka labs prieks kādā labu esat gaisa rīgā aiz patīk saviem
dara daļu paliek jaunu baltijas iespējas divi pāris izlase vairākas liekas domā
grupa rezultātā latviju super skaits citām visā pilsēta iespēju sarakstā
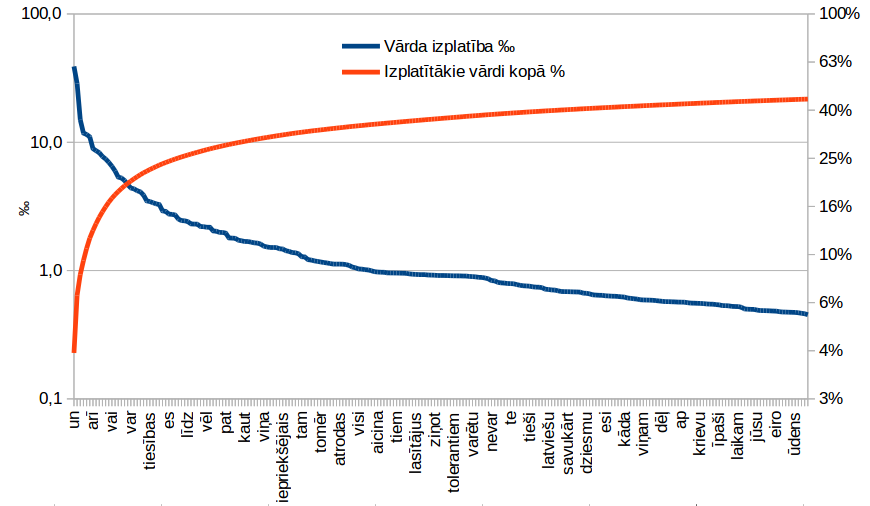
Šo vārdu izplatība ar dilstošu kāpinātāju eksponenciāli samazinās no 40‰ līdz 0,3‰ un ir tipisks "resnās astes sadalījums". Tas, nozīmē, ka:
- tūkstošiem vārdu pēc pirmajiem dažiem desmitiem ir apmēram vienādi reti izplatīti, un "biežāk sastopamie" gūst tikai nelielu pārsvaru pār citiem,
- izvēloties citu teksta avotu, nelielu pārsvaru iegūst pavisam cits, attiecīgam avotam raksturīgs vārdu krājums.
Ņemiet vērā, ka Y ass grafikā ir ar logaritmisku mērogu (klikšķiniet uz attēla, lai to apskatītu lielāku):
Ciparu izplatība
No teksta parauga atlasot vienciparu skaitļus, to sadalījums atbilst Benforda likumam — 1 ir biežāk sastopams par 2, kas savukārt ir izplatītāks par 3 u.t.t. Benforda likums neko nesaka par 0, bet manis iegūtajā saturā nulle ir vismazāk izplatīts cipars.
| Cipars | Skaits |
|---|---|
| 1 | 40747 |
| 2 | 36839 |
| 3 | 27807 |
| 4 | 23228 |
| 5 | 21465 |
| 6 | 16362 |
| 7 | 13682 |
| 8 | 12197 |
| 9 | 11088 |
| 0 | 7220 |
Sekojošā attēlā ciparu sadalījums ir parādīts grafikā (klikšķiniet uz attēla, lai to apskatītu lielāku):
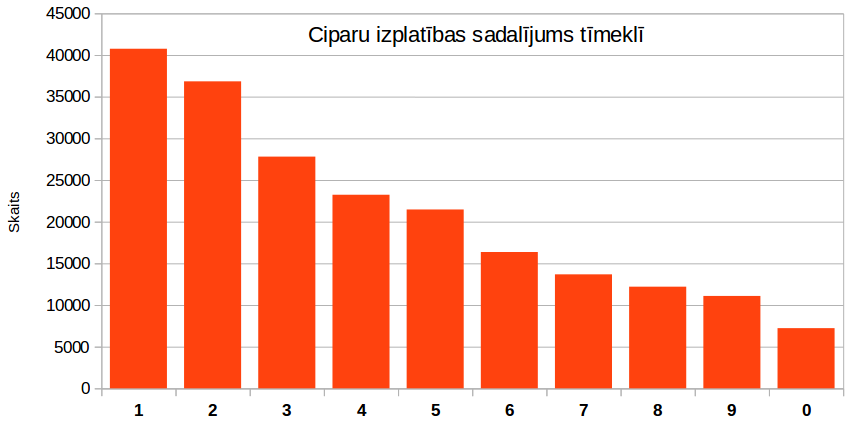
(Benforda likumu mēdz izmantot auditori, pārbaudot, vai iesniegtie grāmatvedības dati nav sagrozīti, jo patiesiem datiem Benforda likums ir spēkā, bet sagrozītiem visi cipari parasti ir vienlīdz izplatīti.)
Dažas interesantas sakarības
Šeit dažādi vārdi ir sagrupēti pēc tematiem un sakārtoti pēc to skaita apkopotajā saturā.
Laika apstākļi
- lietus 780, sniegs 373, negaiss 87, saulains 72, mākoņains 40;
- silts 243, karsts 140, auksts 94, vēss 91;
- silti 105, siltāks 96, auksti 37, aukstāks 15;
- ārā 2421, iekšā 1180.
- tumšs 154, gaišs 64 (protams, runa var iet par daudz ko citu, bet tomēr...)
Laika ritums
- diena 2668, nakts 898, vakars 367, rīts 60;
- dienā 2126, vakarā 928, naktī 746, rītā 383;
- tagad 11967, vēlāk 3419, agrāk 1970;
- ir 297076, bija 44876, būs 16959;
- iepriekš 2561, turpmāk 1414;
- tagad 11967, nekad 4275, nākotnē 587, pagātnē 303;
- ātri 2171, ātrāk 1092, lēni 279, lēnāk 84;
- rudens 317, pavasaris 251, vasara 198, ziema 143;
Nedēļas dienas:
sestdiena 85 piektdiena 69 svētdiena 51 pirmdiena 48 ceturtdiena 35 otrdiena 30 trešdiena 25
Dzīvi un cilvēkus raksturojoši vārdi
- ir 297076, nav 61922;
- labi 12317, labāk 5819, labs 2960, slikti 1846, slikts 522, sliktāk 274;
- patīk 2890, nepatīk 1638, riebjas 274;
- balts 448, melns 406, pelēks 120.
- sauss 131, mitrs 100, slapjš 24;
- jauns 1158, vecs 337, vecāks 121, jaunāks 26 (protams, "vecāks" var lietot arī, norādot uz tēti vai mammu);
- lētāk 233, dārgs 228, lēti 179, dārgi 161, dārgāk 122, lēts 118;
- priecīgs 221, jautrs 48, drūms 44, bēdīgs 13;
- mājās 4291, darbs 2050, darbā 1039, atpūtā 74, atpūta 72;
- Līgo 136, Lieldienas 82, Ziemassvētki 66, kapusvētki 2;
- atcerēties 552, mācīties 523, mācīt 284, aizmirst 277;
- kāzas 183, bēres 24, dzimšana 21, miršana 4;
- izbraukt 242, aizbraukt 154, iebraukt 44, atbraukt 44;
- draugs 607, pretinieks 392, ienaidnieks 205, sabiedrotais 52;
- cīnīties 1387, karā 641, karš 562, miers 387, mierā 217, padoties 69;
- dzīvot 4895, dzīve 1297, nāve 248, nomira 236, mirt 221, piedzima 151, dzimt 13.
Valsts un reliģija
- prezidents 1664, ministrs 846, deputāts 534, premjerministrs 145, spīkers 5;
- pozīcija 124, frakcija 63, opozīcija 63, koalīcija 43;
- Valstij (vienvārdīgie) piederošie uzņēmumi:
Lattelecom 458, LDz 144, LMT 103, AirBaltic 128, LVM 119, Latvenergo 108; - valsts 18485, baznīca 856, reliģisks 63, valstisks 196, garīgs 23, laicīgs 2;
- musulmanis 80, ateists 67, katolis 14, pareizticīgais 2, luterānis 2, budists 7, hinduists 1.
Ģeogrāfija
- Latvijas 25307, pasaules 9893, ASV 5915, Rīgas 8928, Eiropas 7856, Krievijas 7036.
- Pilsētas: Rīga 1622, Ventspils 1226, Daugavpils 827, Liepāja 305, Salaspils 234;
- kalns 437, līcis 321 (var būt arī divdabis), ieleja 130, rags 134 (var būt arī dzīvnieka daļa), paugurs 70, ieplaka 38;
- jūra 687, ezers 1295, upe 719, okeāns 286, strauts 73, peļķe 3.
Dzimumu raksturojoši vārdi
- Izplatītākie vīriešu vārdi:
Jānis 2219, Māris 830, Andrejs 728; - Izplatītākie sieviešu vārdi:
Anna 379, Marija 715, Kristīne 592. - sieviete 1531, sieviešu 1280, vīriešu 898, vīrietis 886;
- priekšnieks 353, direktors 354, direktore 173, priekšniece 13, padotais 9, padotā 2;
- ārsts 534, skolotājs 239, skolotāja 212, ārste 167;
- dēls 1071, meita 598, brālis 455, māsa 252;
- vīrs 1233, sieva 780;
- māte 1506, tēvs 1227, mamma 822, tētis 533.
Nosaukumi
- Tehnoloģiju uzņēmumi:
Facebook 724, Twitter 738, Google 686, Apple 390, Microsoft 225, IBM 108, Tele2 71, Samsung 52, Nokia 63, HP 41, Dell 15; - Operētājsistēmas:
Windows 518, Linux 172, Android 124, iOS 54; - Auto firmas:
Audi 1497, BMW 451, VW+VolksWagen 388, Toyota 221, Ford 190, Renault 177, Nissan 149, Volvo 141, Honda 98, Fiat 67, Hyundai 61, VAZ 27 (Hyundai gan varētu likt arī pie tehnoloģiju uzņēmumiem.) - Degvielas uzpildes stacijas:
Statoil 25, Neste 19, Lukoil 11; - Dižveikali:
Rimi 490, Maxima 255, Elvi 53;
Angļu valoda
Izplatītākie vārdi angļu valodā:
the 34169, a 23439, and 17557, of 14228, in 9714, is 6653, with 4455, news 4257, from 4147, at 4003,
Krievu valoda
Izplatītākie vārdi krievu valodā:
и 13682, в 8284, как 3283, что 3127, это 1601, я 1555, мне 1426, за 1410, для 1322, у 1159
Created by Valdis Vītoliņš on 2016-05-13 10:19
Last modified by Valdis Vītoliņš on 2021-04-13 14:27


